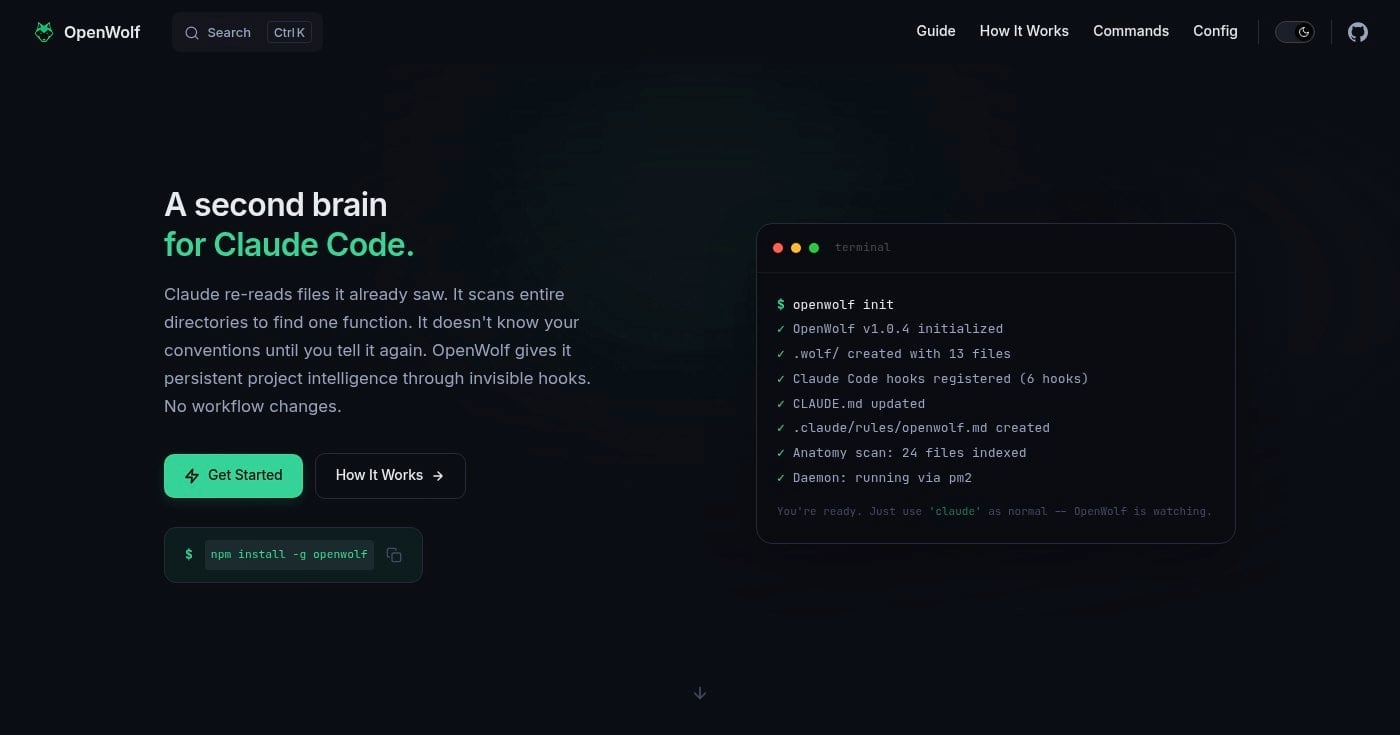
What Is OpenWolf? The Persistent Memory Layer for Claude Code
OpenWolf is open-source middleware that gives Claude Code persistent project memory, cutting token usage by up to 80%. Here's how it works.
Updated 9 min read
OpenWolf is open-source middleware that gives Claude Code persistent project memory, cutting token usage by up to 80%. Here's how it works.
Developers using Claude Code lose up to 99.4% of their tokens to input, not output. The model re-reads the same files over and over because it has no memory of what it already saw.
OpenWolf fixes this. It's a free, open-source middleware layer that gives Claude Code a persistent project brain: a file index, a self-learning memory, and token tracking, all through invisible hooks that fire without changing your workflow.
In this guide, you'll learn what OpenWolf is, how it works, and why it matters if you're hitting Claude Code usage limits or want to make every session sharper from the first prompt.
OpenWolf is an open-source middleware tool for Claude Code that adds persistent project intelligence without changing how you work. It describes itself as "a second brain for Claude Code."
The core problem it solves: Claude Code works blind. It doesn't know what a file contains until it opens it. It can't tell a 50-token config from a 2,000-token module, and it has no memory of your coding preferences or past corrections between sessions.
OpenWolf plugs into Claude Code's lifecycle hook system to intercept every file read and write. Before Claude opens a file, OpenWolf shows it a summary and token estimate. If that's enough context, the full read gets skipped. After every session, what Claude learned is written to disk so the next session starts with a full picture of your project.
The tool was built by the Cytostack team after tracking 132 Claude Code sessions across 20 projects. The data showed that 71% of all file reads were redundant, files Claude had already opened in that same session. OpenWolf was built to fix that specific problem.
OpenWolf installs globally and initializes inside any project with two commands:
npm install -g openwolf
cd your-project && openwolf init
After that, you use claude exactly as before. OpenWolf runs in the background.
openwolf init scans your project and creates a .wolf/ directory containing a file index, learning memory files, hook scripts, and configuration. It also registers 6 hooks with Claude Code and updates your CLAUDE.md so Claude reads the OpenWolf context at session start.
Six Node.js hooks fire on every Claude action. They sit between you and Claude, passing information without blocking or requiring your input:
Hook trigger | Hook file | What it does |
|---|---|---|
Session start |
| Creates session tracker, logs to memory |
Pre file read |
| Warns on repeated reads, surfaces anatomy info |
Pre file write |
| Checks cerebrum Do-Not-Repeat patterns |
Post file read |
| Estimates and records token usage |
Post file write |
| Updates anatomy, appends to memory |
Session stop |
| Writes session summary to token ledger |
All hooks are pure file I/O. No network calls, no additional AI inference, no cost beyond disk writes.
When you correct Claude (fix a variable name, tell it not to mock the database, clarify how auth middleware reads config), that correction gets logged to cerebrum.md. The next time Claude is about to write code, the pre-write hook checks that file and flags any known mistakes before they happen again.
OpenWolf provides four distinct layers of project intelligence:
Layer | File | What it tracks |
|---|---|---|
Structural |
| File map with descriptions and token estimates |
Behavioral |
| Preferences, conventions, Do-Not-Repeat list |
Historical |
| Session logs, bug fix archive |
Economic |
| Lifetime token usage with session breakdown |
Each layer builds on the previous. The structural layer reduces redundant reads. The behavioral layer prevents repeated mistakes. The historical layer makes bug fixes searchable.
The economic layer shows you exactly where your subscription goes.
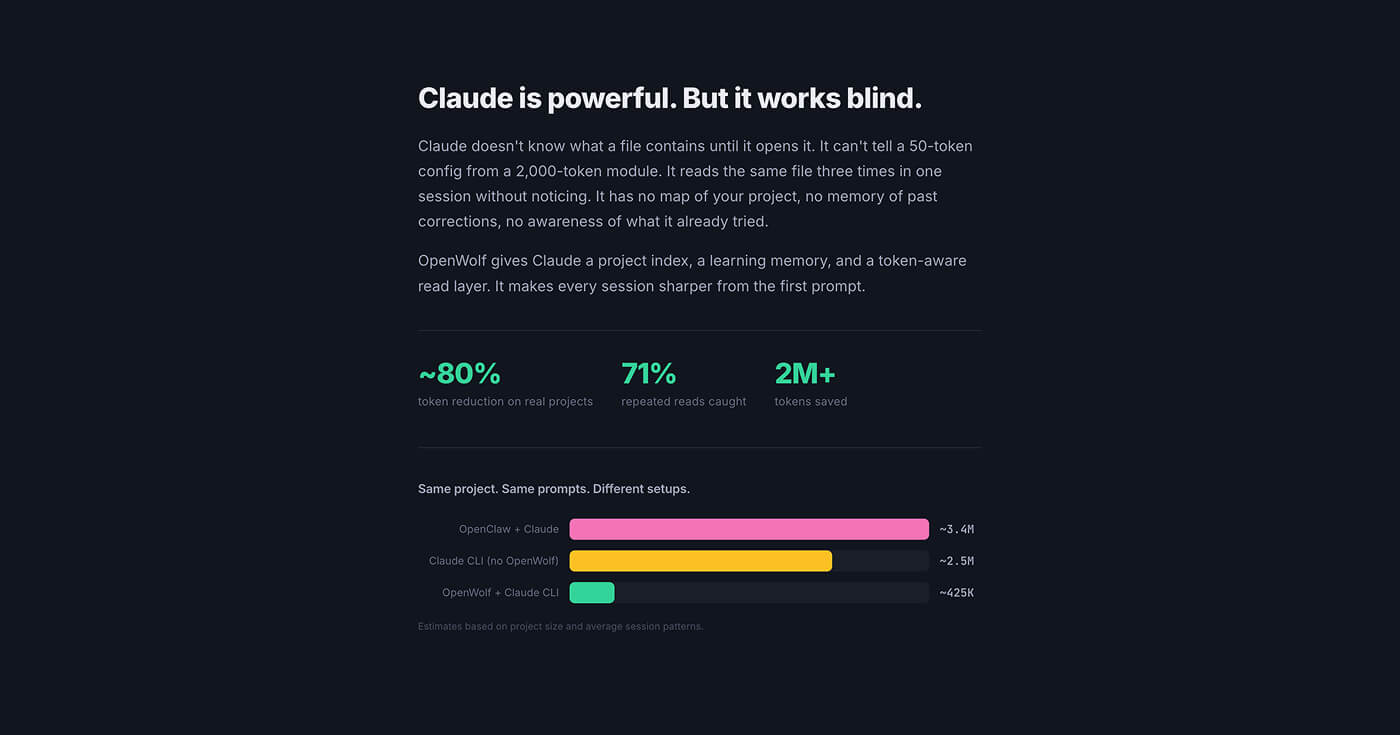
The token comparison on OpenWolf's homepage shows the same project and same prompts producing ~2.5M tokens with bare Claude CLI and ~425K tokens with OpenWolf.
That's a reduction of roughly 80%. Across 20 projects and 132 sessions, the team measured an average reduction of 65.8%. Results depend on project size and session patterns, but the direction is consistent.
Most context-optimization approaches require you to write custom CLAUDE.md files, structure prompts differently, or run commands before each session. OpenWolf requires none of that.
You type claude and it works. The hooks fire invisibly, the memory updates automatically, and you interact with Claude exactly as you did before.
Claude Code normally starts each session with zero knowledge of your project conventions. After a few sessions with OpenWolf, the cerebrum.md file contains your coding style preferences, known bug fixes, and a Do-Not-Repeat list of mistakes Claude has made before.
That knowledge persists and applies immediately at the start of every new session.
Everything stays on your machine. OpenWolf makes no network requests and calls no external APIs. Your project's file index, session logs, and preferences never leave your local environment.
For teams working on sensitive codebases, this matters.
The token-ledger.json file tracks every token used across every session. You can see exactly which files consume the most context, which sessions ran long, and where your subscription budget actually goes.
OpenWolf dashboard surfaces this as a real-time view.
OpenWolf hooks directly into Claude Code's lifecycle event system. It doesn't work with Cursor, Windsurf, GitHub Copilot, or other AI coding tools.
If your team uses a mix of tools, OpenWolf only benefits the Claude Code users.
Installation depends on a global npm install. Teams using non-JavaScript stacks need Node.js on their machines even if their project doesn't use it.
The runtime dependency is lightweight, but it's an extra install step for some setups.
OpenWolf was released in March 2026 and had 223 GitHub stars at time of writing. It's a young tool with a single primary contributor. Production use should come with the expectation that APIs and file formats may change as the project matures.
OpenWolf is licensed under AGPL-3.0, which requires derivative works to be open-source under the same license. For most developers using it as a developer tool (not embedding it into a commercial product), this isn't a concern.
Teams building products on top of OpenWolf should review the license terms.
Claude Code's hook system is currently the only integration point OpenWolf uses. As other AI coding tools add similar lifecycle hook APIs, the architecture of OpenWolf could extend to cover multi-tool environments where developers switch between agents.
The .wolf/ directory currently lives per-developer per-project. A shared team memory layer, where corrections and preferences sync across a development team's instances, is a natural extension that would multiply the value of the behavioral learning layer.
Right now, the anatomy descriptions in anatomy.md are generated at init time and updated after writes. As embedding-based file summarization improves, automated semantic descriptions (what a file does, not just what it contains) could make the file index substantially more useful.
npm install -g openwolf in your terminal..wolf/ directory and registers hooks.OpenWolf addresses one of the most concrete inefficiencies in AI-assisted development: the fact that Claude Code restarts from zero every session, re-reading files it already processed and re-learning preferences you've already stated.
By hooking into Claude's lifecycle to maintain a persistent project index and learning memory, it reduces token waste and makes every session incrementally smarter.
It's early-stage software with a small but growing community. If you're hitting Claude Code usage limits mid-week, or simply want more signal per session with less redundant context overhead, the two-command install is worth the experiment.

Compare 12 AI voice assistants for personal and business use. Real pricing, latency benchmarks, and true cost breakdowns for Siri, Vapi, Retell AI, and more.
Compare 14 AI app builders by buyer type, real pricing, and production-readiness. Includes hidden costs, HIPAA picks, and tools rival listicles haven't listed yet.

Cursor wins for inline autocomplete and IDE-native workflows; Claude Code wins for autonomous agents, large refactors, and CI/CD pipelines. Both start at $20/mo. Here's how to pick—or use both.