Google Launches Gemma 4 with Apache 2.0 License and Gemini 3 Architecture
Google launches Gemma 4 in four sizes under Apache 2.0, built on Gemini 3 architecture. The 31B model ranks #3 among all open models on Arena AI.
Updated 5 min read

Google launches Gemma 4 in four sizes under Apache 2.0, built on Gemini 3 architecture. The 31B model ranks #3 among all open models on Arena AI.
Google launched Gemma 4 on April 2, 2026, releasing four open-weight models built on the same research and architecture as Gemini 3. The new family spans smartphones to data center GPUs and, for the first time, ships under an Apache 2.0 license.
The licensing change is the most consequential part of the release. Gemma 1, 2, and 3 shipped under a custom Gemma license with commercial and usage restrictions that frustrated developers. Apache 2.0 removes those restrictions entirely, allowing unrestricted commercial use, modification, and redistribution. It puts Gemma on equal footing with Meta's Llama on openness.
"You gave us feedback, and we listened," the Gemma 4 announcement states.
Gemma 4 launches in four sizes optimized for different hardware tiers.
The E2B (Effective 2B) and E4B (Effective 4B) models target edge devices. Built in close collaboration with Google's Pixel team and chip partners Qualcomm Technologies and MediaTek, they run completely offline on smartphones, Raspberry Pi, and NVIDIA Jetson Orin Nano devices with near-zero latency. Both models process video, images, and audio natively, and support a 128K-token context window.
The 26B Mixture of Experts model activates only 3.8 billion of its 26 billion parameters during inference, delivering high tokens-per-second on local hardware while fitting on consumer GPUs in quantized form. The 31B Dense model prioritizes raw quality over speed and runs unquantized on a single 80GB NVIDIA H100 GPU.
All four models support function-calling, structured JSON output, and native system instructions for agentic workflows. Code generation runs offline. Context windows reach 256K tokens on the two larger models. Every model in the family handles more than 140 languages.
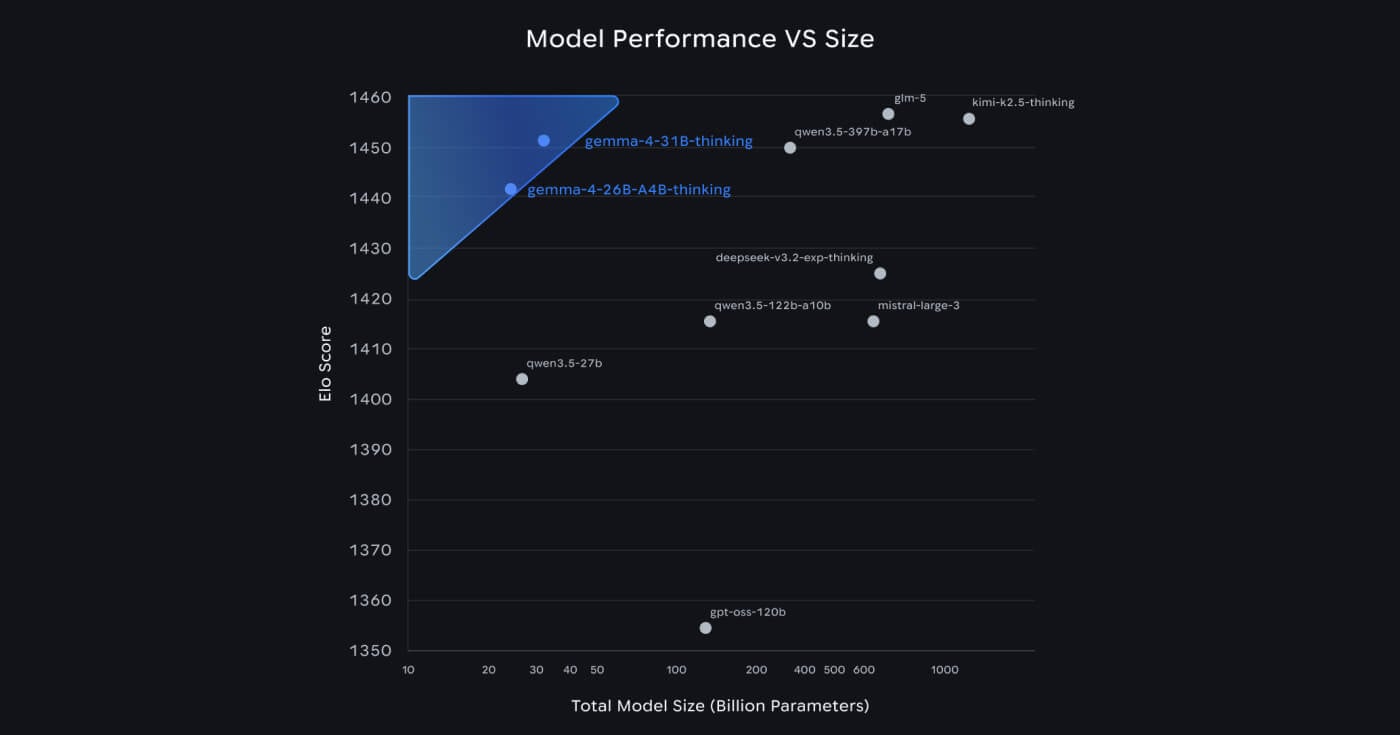
Google claims the 31B Dense model debuted at #3 on the Arena AI text leaderboard among open models, behind GLM-5 and Kimi 2.5, while the 26B MoE holds the #6 spot. Both outperform models 20 times their size on that benchmark, according to Google.
"Gemma 4 is here, and it's packing an incredible amount of intelligence per parameter," CEO Sundar Pichai said at launch.
Google DeepMind CEO Demis Hassabis called the models "the best open models in the world for their respective sizes."
Previous Gemma releases used a custom license that restricted use cases and imposed usage limits, drawing repeated criticism from developers who found the terms incompatible with commercial projects. Ars Technica noted that Google "acknowledged developer frustrations with AI licensing" in making the switch.
Apache 2.0 is the most permissive standard in open-source software. Developers can now build commercial products on Gemma 4, modify the weights, and redistribute them without restriction. The change aligns Google with Meta's approach on Llama and removes a significant adoption barrier for enterprises operating in regulated or sensitive environments that require full data and infrastructure control.
Google reports that Gemma models have been downloaded more than 400 million times since the first release, generating more than 100,000 community variants in what it calls the "Gemmaverse." Projects include BgGPT, a Bulgarian-first language model built by INSAIT, and Cell2Sentence-Scale, a collaboration with Yale University for cancer therapy research.
Gemma 4 has day-one support across the major open-source tooling ecosystem, including Hugging Face (Transformers, TRL, Transformers.js), vLLM, llama.cpp, MLX, Ollama, NVIDIA NIM and NeMo, LM Studio, Unsloth, SGLang, Keras, and Docker.
NVIDIA optimized Gemma 4 across its hardware stack from RTX-powered consumer PCs to the DGX Spark personal AI supercomputer and Jetson Orin Nano edge modules. A community member on Reddit noted that the approximately 5GB RAM floor for E2B and E4B at 4-bit quantization "puts a genuinely capable model on commodity hardware without special hardware."
The 31B and 26B MoE models are available now in Google AI Studio. The E4B and E2B models are in Google AI Edge Gallery. All weights are downloadable from Hugging Face, Kaggle, and Ollama. Android developers can access Gemma 4 via the AICore Developer Preview for forward-compatibility with Gemini Nano 4.
Gemma 4's architecture alignment with Gemini 3 gives it a path to capability improvements as Google's proprietary research advances. The Apache 2.0 switch removes the friction that kept enterprise and sovereign deployments off earlier Gemma versions. The practical question is how quickly the fine-tuning community, which already produced 100,000 Gemma 3 variants, builds on the new base.
Gemma 3 launched in March 2025 and went more than a year without a successor. Gemma 4 ships with a different licensing philosophy and a substantially more capable architecture. How long Google holds this iteration as a stable base before the next release will shape how much the community invests in building on it.

A zero-human company (ZHC) is a business where AI agents handle every operational function without human employees. Learn how it works, real examples earning $6M+ ARR, the tech stack, and a step-by-step guide to building one in 2026.

OpenAI rolled out Chronicle for its Codex macOS desktop app, an opt-in research preview that captures periodic screenshots and stores text summaries locally so Codex understands what a developer is working on without being told each time.

Anthropic's Claude Managed Agents launches in public beta, promising to cut AI agent deployment from months to days with managed cloud infrastructure and built-in orchestration.